
During this lab, you will get a hands-on preview of the Adobe Experience Platform Query Service, which is currently in Alpha testing and will soon be available to Proof of Concept customers.
The Query Service gives users the ability to query datasets in Adobe Experience Platform in support of many different use cases. It is a serverless tool which works on datasets from the solutions across the Experience Cloud and other data loaded into the Experience Platform. It supports SQL queries and connectivity from multiple client applications through its PostgreSQL compatibility. We will focus on datasets produced from Adobe Analytics and a few others.
During this lesson you will learn about Adobe Experience Platform - how to log in, navigate datasets, and connect external clients to Query Service. For this lab, we are using a fictional online retailer called LUMA.

Let's start with logging into the Adobe Experience Platform UI.
Navigate to the Adobe Experience Platform Login Page: https://platform.adobe.com
Sign in with the following credentials:
User Name: L776+[your station number]@adobeeventlab.com
Password: Adobe2019!
Browse Learning Resources
Bringing data from different channels is a tough task for any brand. And in this exercise, LUMA customers are engaging with LUMA on its website, on its mobile app, purchase data is collected by LUMA’s Point of Sale system, and they have CRM and Loyalty data. LUMA is using Adobe Analytics and Adobe Launch to capture data across its website, mobile app as well as POS system, so this data is already flowing into Adobe Experience Platform. Lets begin with exploring all the data for LUMA that already exists on the Platform.
Click on Datasets element in the left navigation panel in the Platform UI
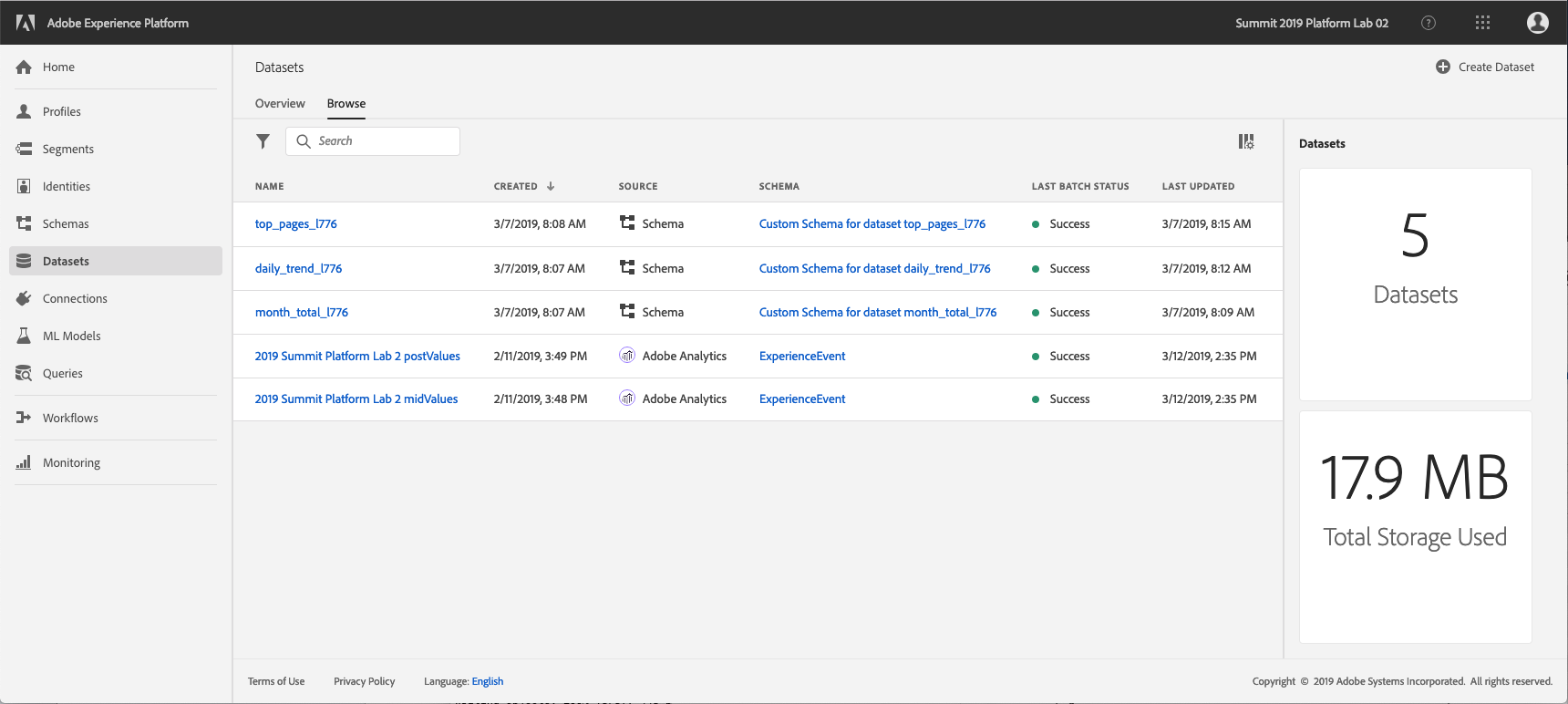
LUMA is using Adobe Analytics to capture Web Behavioral data and this data is available in the platform in “2019 Summit Platform Lab 2 postValues” dataset. Search for “2019 Summit Platform Lab 2 postValues”. As you can see the schema for this dataset if “Experience Event”. Experience Event schema is our standard schema to describe any activity done, which works well to capture web and mobile behavioral data.
Click on the “2019 Summit Platform Lab 2 postValues” to get more details on the dataset.
Dataset Activity tab shows the amount of data transferred from Adobe Analytics today and Last 30 days.
Go back to List of Datasets by clicking on “Datasets” element in the left navigation panel.
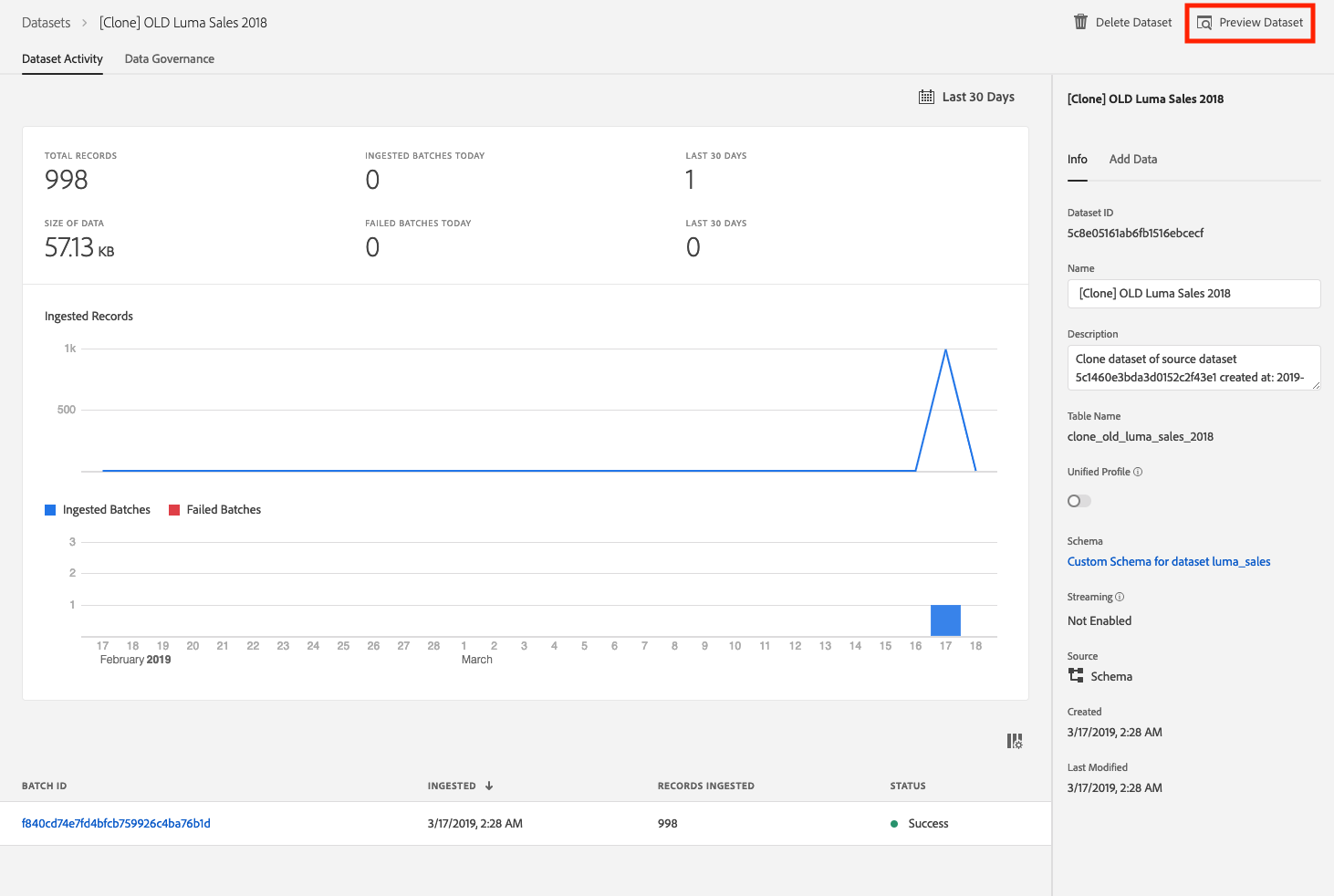
LUMA’s POS data is captured in “Luma Sales” dataset. Search for “Luma Sales” data in search box. Click on dataset name to get dataset details.
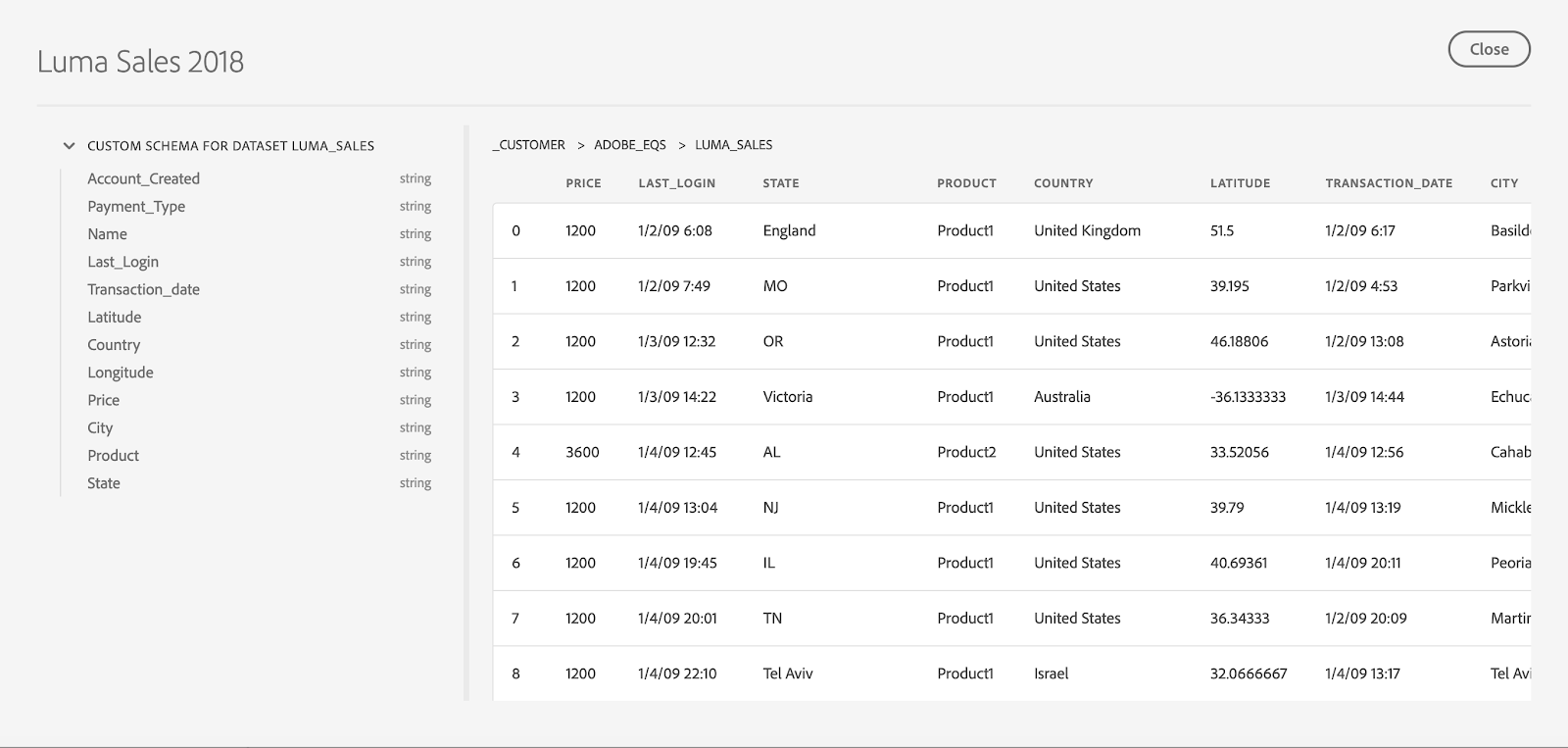
Click on “Preview Dataset” to see a sample of the data stored in “Luma Sales” dataset. Preview shows a sample of the data stored in this dataset. Left panel also shows schema for this dataset.
You will be working with the Alpha version of the Query Service today.
Query Service is accessed by clicking on "Queries" toward the bottom of the left navigation.
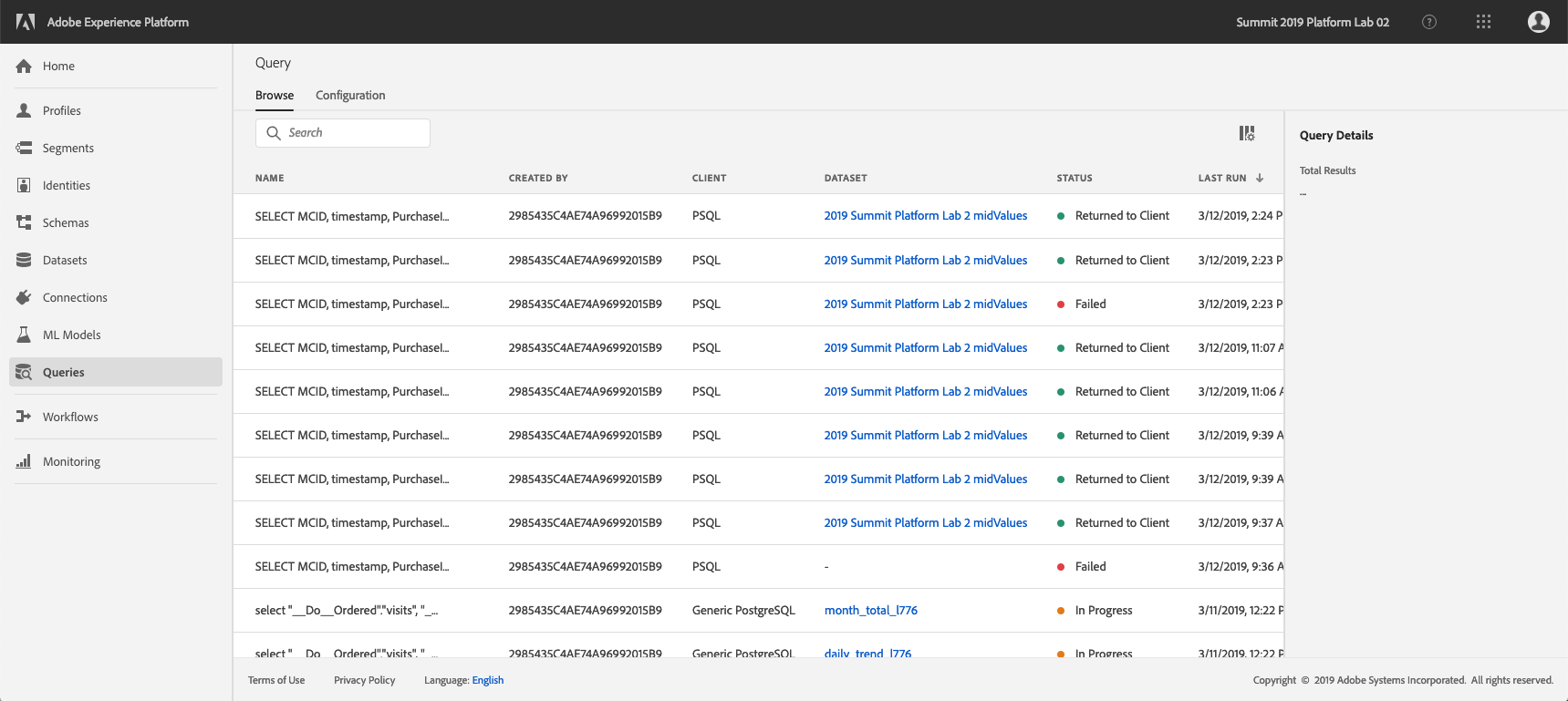
You will see the Query List page, which provides you a list of all the queries run in this organization, with the latest at the top.
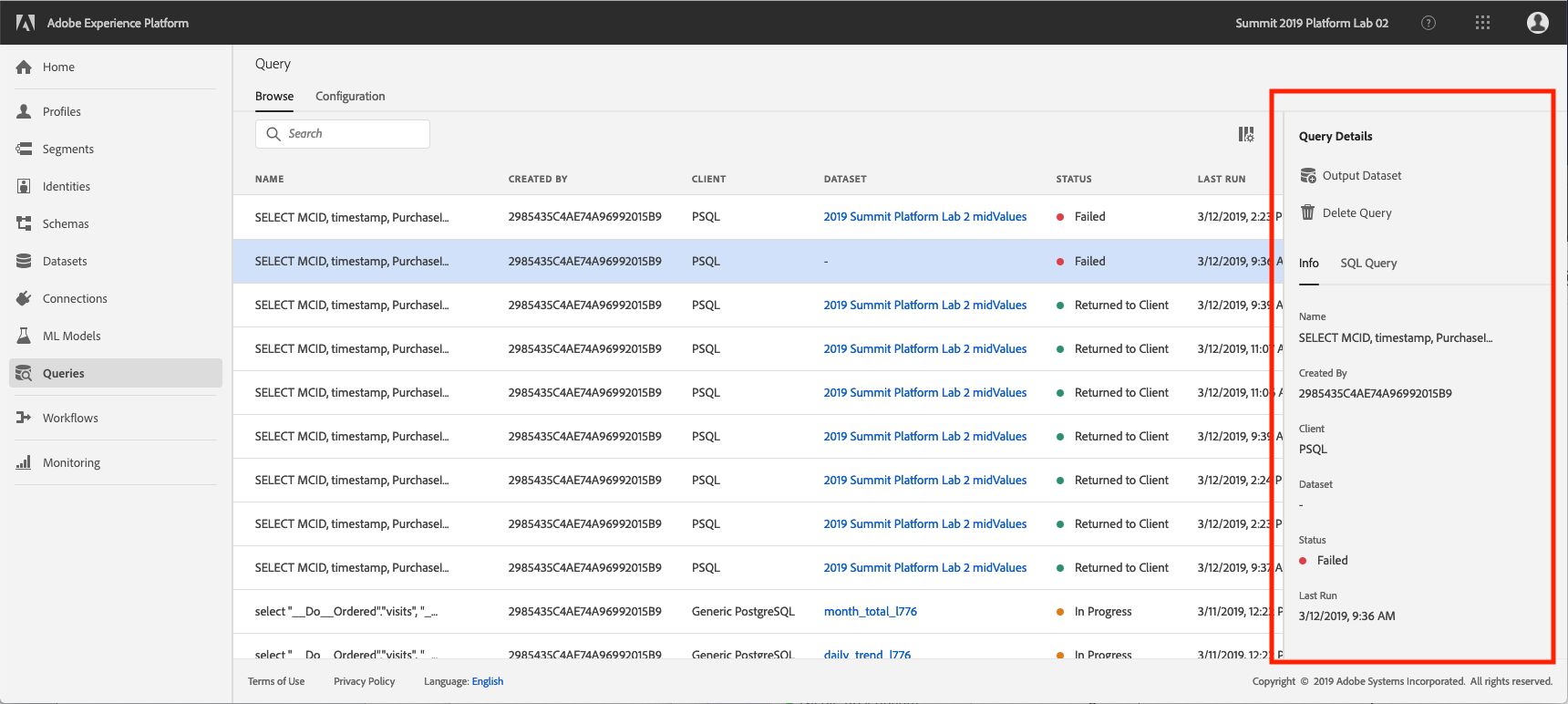
Click on a query from the list and observe the details provided in the right rail
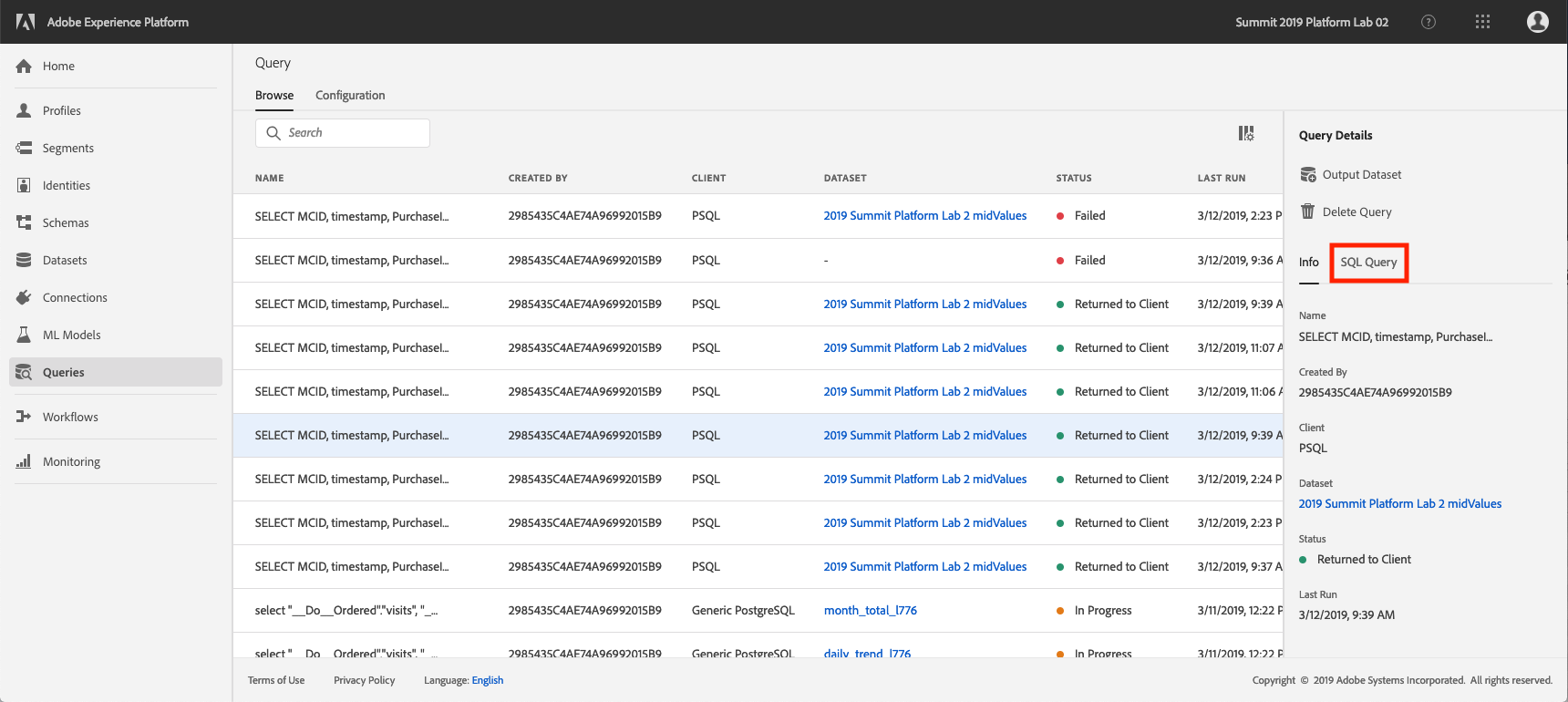
From here you can click on "SQL Query" to see the SQL code for this query.
You can scroll the window to see the entire query, or you can click on the icon highlighted below to copy the entire query to your notepad.
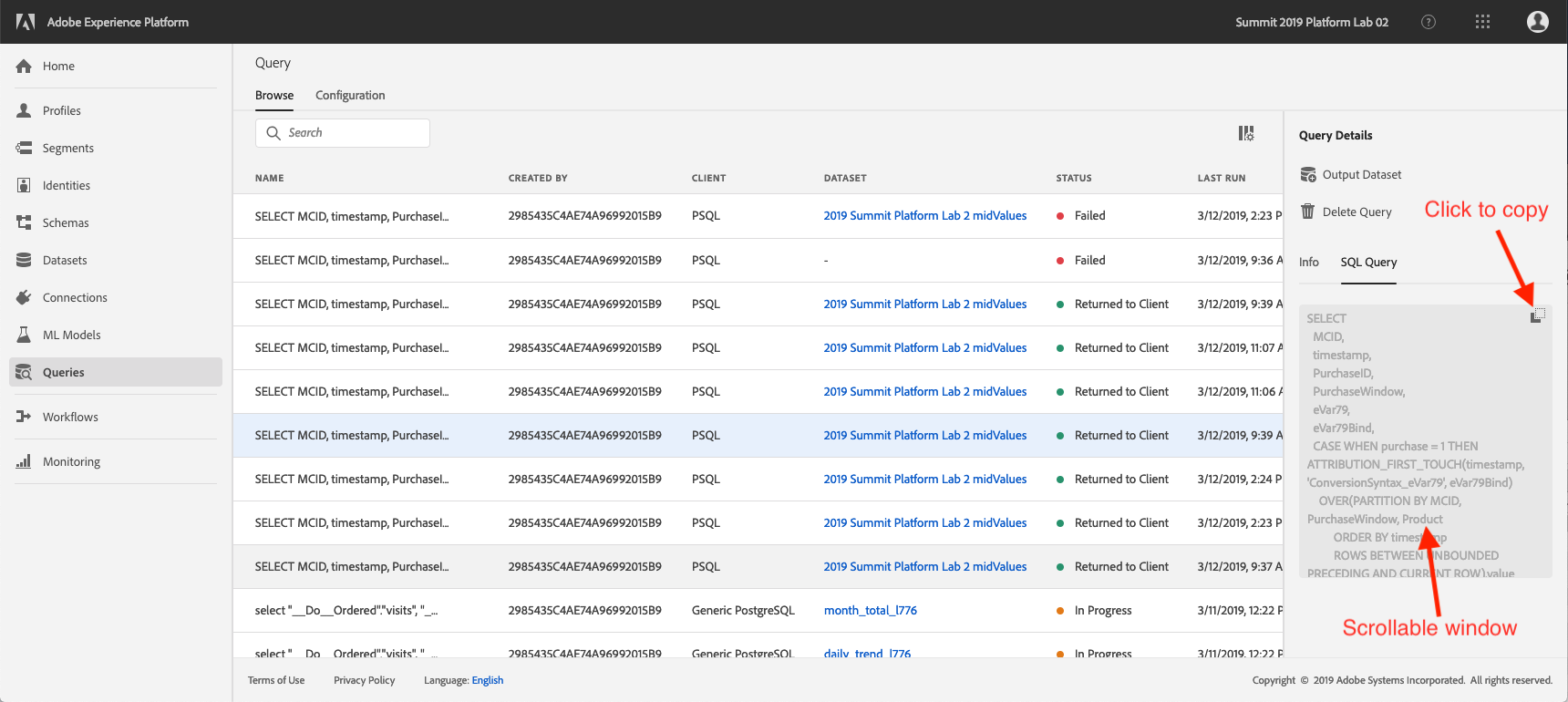
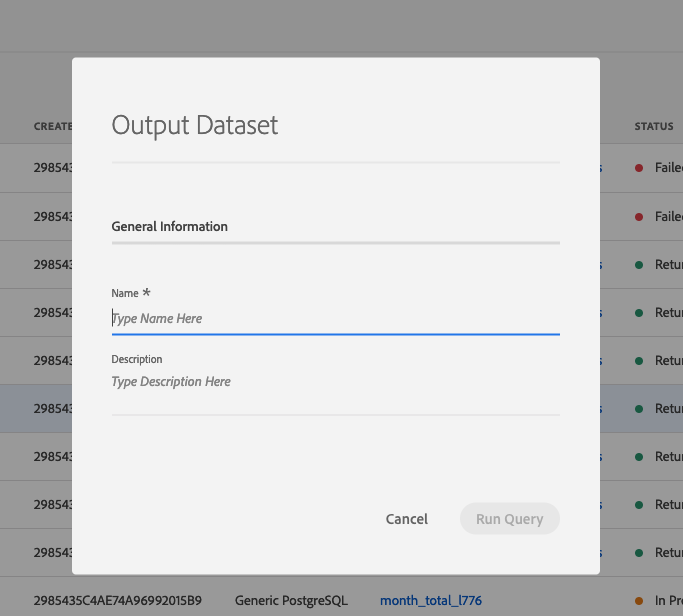
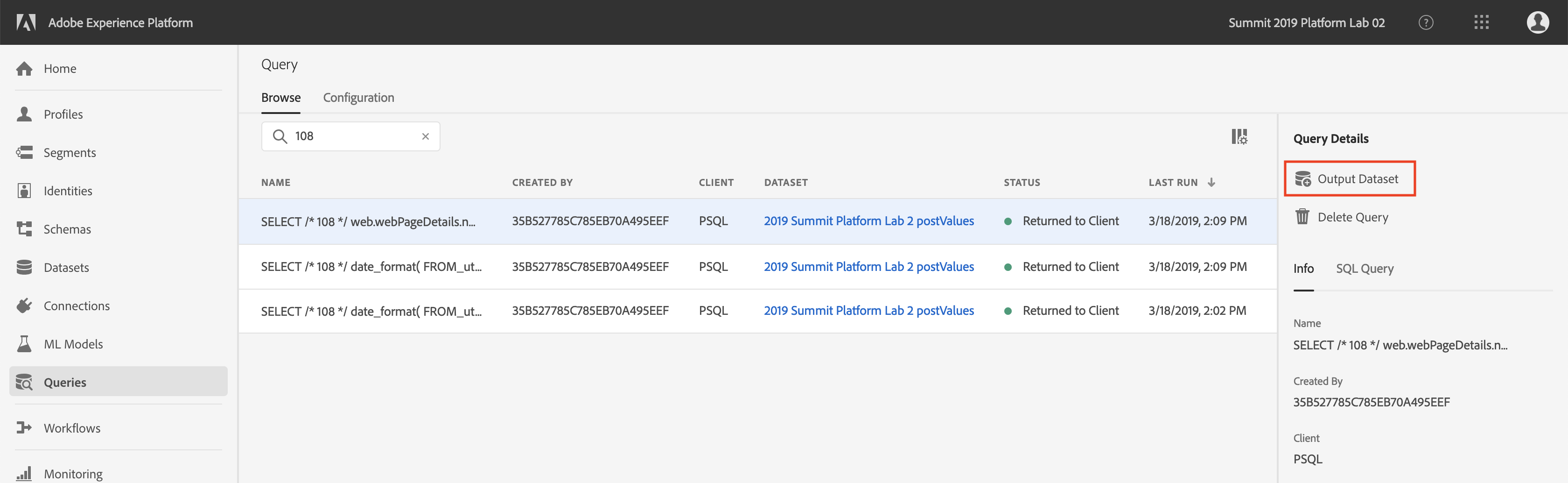
You can click on "Output Dataset" to run a query and generate a dataset on the Platform from the results of the query. For now, don't generate a dataset. We'll do this later.
The general release of Query Service will include a web interface for sumbitting, managing, and scheduling queries. This Alpha version requires that you connect an external client in order to submit queries. Query Service supports clients with a driver for PostgreSQL. In this lab we will be using PSQL, a command-line interface, and Power BI. In this exercise we will connect PSQL. (We'll connect Power BI a little later.)
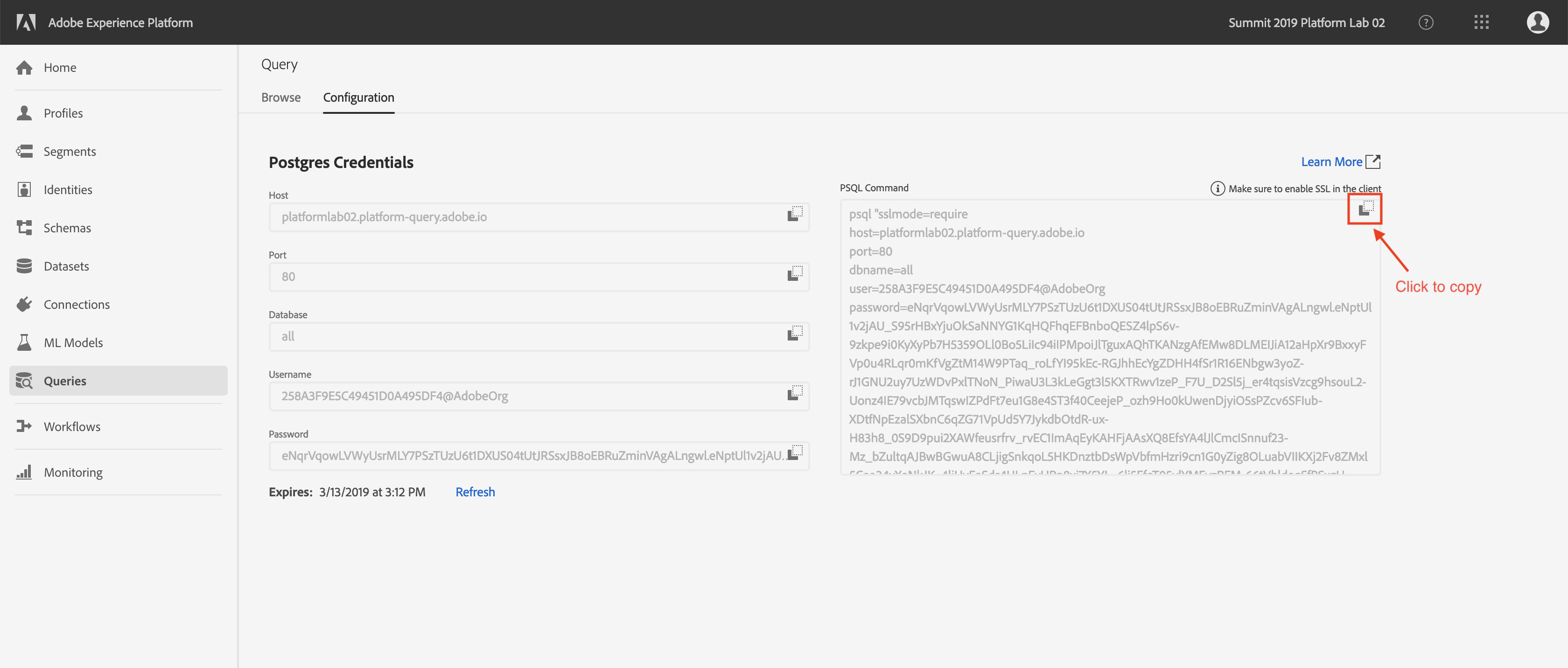
Click on "Configuration" in the top left.
You will see the screen below. The Configuration screen provides server information and credentials for authenticating to Query Service. For now, we will focus on the right side of the screen which contains a connect command for PSQL. Click on the Copy button to copy the command to your clipboard.
Open the command line by hitting the windows key and typing cmd and then clicking on the Command Prompt result.
Paste the connect command and hit enter.
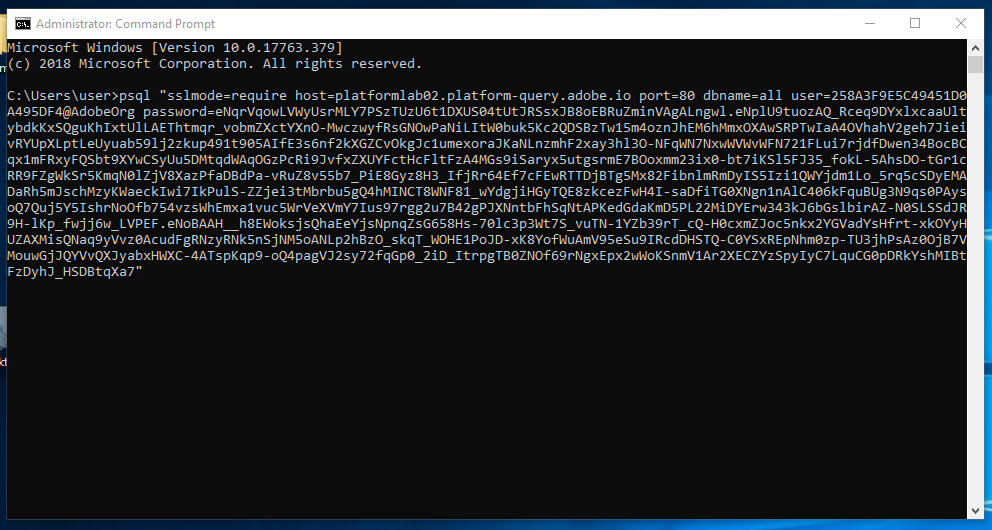
You are now connected to Query Service using PSQL. You can verify that you are connected when you see a prompt that looks like this:

Now you are ready to start submitting queries!
In this lesson you will learn how to use PSQL to retrieve information about the available datasets, how to write a queries for Experience Data Model (XDM), and write your first reporting queries using the Query Service and Adobe Analytics datasets.
In this exercise you will learn about the methods to retrieve information about the available datasets and how to properly retrieve data with a query from an XDM dataset.
See the available tables with \d or SHOW TABLES;
Returns the standard PostgreSQL view
List of relations
Schema | Name | Type | Owner
--------+----------------------------------------+-------+----------
public | x2019_summit_platform_lab_2_midvalues | table | postgres
public | x2019_summit_platform_lab_2_postvalues | table | postgres
(2 rows)
A custom command added to give you a more detail view and presents the table and dataset information
name | dataSetId | dataSet | description | resolved
----------------------------------------+--------------------------+---------------------------------------+-------------+----------
x2019_summit_platform_lab_2_midvalues | 5c61fbd5e1b555152c884557 | 2019 Summit Platform Lab 2 midValues | | false
x2019_summit_platform_lab_2_postvalues | 5c61fbe1e1b555152c884559 | 2019 Summit Platform Lab 2 postValues | | false
(2 rows)
See the root schema for a table \d <TABLENAME>
Table "public.x2019_summit_platform_lab_2_postvalues_1"
Column | Type | Collation | Nullable | Default
------------------+-------------------------------------------------------+-----------+----------+---------
application | x2019_summit_platform_lab_2_postvalues_1_application | | |
timestamp | timestamp | | |
_id | text | | |
productlistitems | anyarray | | |
commerce | x2019_summit_platform_lab_2_postvalues_1_commerce | | |
receivedtimestamp | timestamp | | |
enduserids | x2019_summit_platform_lab_2_postvalues_1_enduserids | | |
datasource | x2019_summit_platform_lab_2_postvalues_1_datasource | | |
web | x2019_summit_platform_lab_2_postvalues_1_web | | |
placecontext | x2019_summit_platform_lab_2_postvalues_1_placecontext | | |
identitymap | pg_proc | | |
marketing | x2019_summit_platform_lab_2_postvalues_1_marketing | | |
environment | x2019_summit_platform_lab_2_postvalues_1_environment | | |
_experience | x2019_summit_platform_lab_2_postvalues_1__experience | | |
device | x2019_summit_platform_lab_2_postvalues_1_device | | |
search | x2019_summit_platform_lab_2_postvalues_1_search | | |
Query an object in a table
=> SELECT endUserIds._experience.mcid
FROM x2019_summit_platform_lab_2_postvalues_1
WHERE endUserIds._experience.mcid IS NOT NULL
LIMIT 1;
mcid
--------------------------------------------------------
(81115342661543836181646812764551792276,"(ECID)",true)
(1 row)
Notice the result is a flattended object rather than a single value? The
endUserIds._experience.mcidobject contains four parameters:id,namespace,xid, andprimary. And when an object is declared as a column it will return the entire object as a string. The XDM schema may be more complex than what you are familiar with but it's very powerful and was architected to support many solutions, channels, and use cases.
Try querying for endUserIds._experience.mcid.id. Notice the additional ".id" added to further scope the column. This will return the value for that field within the object.
=> SELECT endUserIds._experience.mcid.id
FROM x2019_summit_platform_lab_2_postvalues_1
WHERE endUserIds._experience.mcid IS NOT NULL
LIMIT 1;
id
----------------------------------------
81115342661543836181646812764551792276
(1 row)
Consider these other examples of objects and fields for XDM in the Adobe Analytics datasets. Take a minute to open Notepad++, paste in the previous query, and select some of the values below:
XDM Items _experience.analytics.session (object) _experience.analytics.session.num (field) _experience.analytics.session.depth (field) _experience.analytics.event1to100 (object) _experience.analytics.event1to100.event2 (object) _experience.analytics.event1to100.event2.value (field) _experience.analytics.customDimensions.evars (object) _experience.analytics.customDimensions.evars.evar11 (field)
In this exercise you will create your first set of reporting queries on the Adobe Analytics data. We will walk through replicating traffic and commerce type reporting you would see in Adobe Analytics.
Let us start by creating a trended report for common traffic metrics.
Create a SELECT statement for the COUNT of page views trended by time. Use these columns timestamp and web.webPageDetails.pageviews.value found in the x2019_summit_platform_lab_2_postvalues dataset.
Pro Tip! Always declare a LIMIT when you first start designing your query. The Adobe Analytics dataset (and other XDM ExperienceEvent based datasets) contain a very high volume of records.
=> SELECT
timestamp AS Time,
SUM(web.webPageDetails.pageviews.value) AS pageViews
FROM x2019_summit_platform_lab_2_postvalues_1
GROUP BY Time
LIMIT 10;
Time | pageViews
----------------------+-----------
2019-02-15 22:40:46.0 | 1.0
2019-02-19 03:09:37.0 |
2019-02-12 21:23:17.0 |
2019-02-12 19:08:36.0 |
2019-02-14 11:46:52.0 | 1.0
2019-02-15 18:28:30.0 |
2019-02-21 19:20:05.0 | 1.0
2019-02-15 22:48:47.0 | 1.0
2019-02-21 16:33:57.0 |
2019-02-21 18:02:55.0 | 1.0
(10 rows)
You will notice the timestamp column is expressed all the way down to the second which doesn't help produce a readable result. Let's use the date_format(<INPUT_COLUMN>, <RETURN_FORMAT>) function to parse the timestamp and return the day portion.
date_format( timestamp , 'yyyy-MM-dd')
=> SELECT
date_format( timestamp , 'yyyy-MM-dd') AS Day,
SUM(web.webPageDetails.pageviews.value) AS pageViews
FROM x2019_summit_platform_lab_2_postvalues_1
GROUP BY Day
LIMIT 10;
Day | pageViews
-----------+-----------
2019-02-13 | 58.0
2018-12-16 | 3.0
2019-02-25 | 2.0
2019-02-22 | 83.0
2019-02-15 | 198.0
2019-02-12 | 74.0
2019-02-23 | 13.0
2019-02-18 | 33.0
2019-02-16 | 9.0
2019-02-17 | 8.0
(10 rows)
Now we are making progress! In this next step apply formatting to order the columns. Add an ORDER BY to your query with Day ascending and Page Views descending.
ORDER BY Day ASC, pageViews DESC
=> SELECT
date_format( timestamp , 'yyyy-MM-dd') AS Day,
SUM(web.webPageDetails.pageviews.value) AS pageViews
FROM x2019_summit_platform_lab_2_postvalues_1
GROUP BY Day
ORDER BY Day ASC, pageViews DESC
LIMIT 10;
Day | pageViews
-----------+-----------
2018-12-16 | 3.0
2019-02-11 | 13.0
2019-02-12 | 74.0
2019-02-13 | 58.0
2019-02-14 | 125.0
2019-02-15 | 198.0
2019-02-16 | 9.0
2019-02-17 | 8.0
2019-02-18 | 33.0
2019-02-19 | 155.0
(10 rows)
IMPORTANT The timestamp column found in the Adobe Analytics dataset (and other ExperienceEvent based datasets) is set to the UTC time zone.
Let's apply another important function. The timestamp column is set to the UTC time zone. You will need to apply an offset in your query. To do this we will use the from_utc_timestamp(<INPUT_COLUMN>, <TIME_ZONE>) function. Go head and add this function using a time zone value of PST.
from_utc_timestamp( timestamp , 'PST')
=> SELECT
date_format( from_utc_timestamp( timestamp , 'PST') , 'yyyy-MM-dd') AS Day,
SUM(web.webPageDetails.pageviews.value) AS pageViews
FROM x2019_summit_platform_lab_2_postvalues_1
GROUP BY Day
ORDER BY Day ASC, pageViews DESC
LIMIT 10;
Day | pageViews
-----------+-----------
2018-12-16 | 3.0
2019-02-11 | 17.0
2019-02-12 | 77.0
2019-02-13 | 72.0
2019-02-14 | 150.0
2019-02-15 | 153.0
2019-02-16 | 10.0
2019-02-17 | 9.0
2019-02-18 | 120.0
2019-02-19 | 99.0
(10 rows)
For the better performance and a faster query let's add a WHERE clause to the SQL statement using special columns. These columns are _ACP_YEAR, _ACP_MONTH, and _ACP_DAY. They represent date elements that correspond to the logical partitions used in the Experience Platform to organize the data files of the dataset.
WHERE _ACP_YEAR = 2019
IMPORTANT These special columns are based on UTC so keep that in mind when querying near the day, month, and year boundaries.
=> SELECT
date_format( from_utc_timestamp( timestamp , 'PST') , 'yyyy-MM-dd') AS Day,
SUM(web.webPageDetails.pageviews.value) AS pageViews
FROM x2019_summit_platform_lab_2_postvalues_1
WHERE _ACP_YEAR = 2019
GROUP BY Day
ORDER BY Day ASC, pageViews DESC
LIMIT 10;
Day | pageViews
-----------+-----------
2019-02-11 | 17.0
2019-02-12 | 77.0
2019-02-13 | 72.0
2019-02-14 | 150.0
2019-02-15 | 153.0
2019-02-16 | 10.0
2019-02-17 | 9.0
2019-02-18 | 120.0
2019-02-19 | 99.0
2019-02-20 | 84.0
(10 rows)
You are doing great! You've learned how to write a query for the Query Service. Learned about a few more XDM fields in the Adobe Analytics dataset. And time functions and columns that will help you generate accurate reporting and improve performance. Let's keep building off of this query.
Add column aggregations to generate the visitors and visits by using the COUNT (DISTINCT <INPUT_COLUMN>) aggregator. We will use the following columns from the Analytics dataset:
endUserIds._experience.aaid.id for the Analytics visitor ID
_experience.analytics.session.num for the Analytics visit number.
IMPORTANT The
_experience.analytics.session.numcolumn is only populated in the "postvalues" Analytics dataset. You may have noticed the "midvalues" and "postvalues" appended to the table names. Both datasets are populated with data from the x2019_summit_platform_lab_2 report suite but the data is sourced at different processing stages from within Adobe Analytics. The "midvalues" have data processing applied (Analytics VISTA and Processing Rules) but no attribution. And the "postvalues" have the same data processing with the addition of attribution (aka persistence of eVars) and include vistor profile based fields (visit number, visit page depth, etc).
COUNT (DISTINCT endUserIds._experience.aaid.id) AS visitors
COUNT (DISTINCT endUserIds._experience.aaid.id || _experience.analytics.session.num) AS visits
Pro Tip! In the Query Service the
||operator can be used to quickly concatenate columns to create unique groupings
=> SELECT
date_format( from_utc_timestamp( timestamp , 'PST') , 'yyyy-MM-dd') AS Day,
COUNT (DISTINCT endUserIds._experience.aaid.id) AS visitors,
COUNT (DISTINCT endUserIds._experience.aaid.id || _experience.analytics.session.num) AS visits,
SUM(web.webPageDetails.pageviews.value) AS pageViews
FROM x2019_summit_platform_lab_2_postvalues_1
WHERE _ACP_YEAR = 2019
GROUP BY Day
ORDER BY Day ASC, pageViews DESC
LIMIT 10;
Day | visitors | visits | pageViews
------------+----------+--------+-----------
2019-02-11 | 7 | 8 | 17.0
2019-02-12 | 17 | 23 | 77.0
2019-02-13 | 16 | 18 | 72.0
2019-02-14 | 25 | 35 | 150.0
2019-02-15 | 14 | 20 | 153.0
2019-02-16 | 3 | 7 | 10.0
2019-02-17 | 5 | 8 | 9.0
2019-02-18 | 9 | 14 | 120.0
2019-02-19 | 19 | 29 | 99.0
2019-02-20 | 22 | 33 | 84.0
(10 rows)
In the last step of the prior exercise we made reference to the "midvalues" and "postvalues" datasets. Both datasets are populated with data from the x2019_summit_platform_lab_2 report suite but the data is sourced at different processing stages from within Adobe Analytics. The "midvalues" have data processing applied (Analytics VISTA and Processing Rules) but no attribution. And the "postvalues" have the same data processing with the addition of attribution (aka persistence of eVars) and include visitor profile based fields (visit number, visit page depth, etc).
The reason we publish both datasets into Experience Platform is to provide you with the most flexibility. The postvalues dataset makes it easier for you to reproduce the reporting found in the Adobe Analytics experience. And the midvalues dataset opens the possibility for new types of reporting that include, but not limited to, applying changes to sessionization (generation of visits) and attribution. And also this "midvalues" dataset provides the foundation to support stitching of multiple report suites and other data sources.
In this exercise we will look at the midvalues dataset. Explore one of the Adobe Defined Functions provided in the Query Service by applying sessionization directly in your query.
For reference see the ADF Functions beta documentation
Create a SELECT statement to return a list of 10 Analytics ids and visit numbers. Use the columns endUserIds._experience.aaid.id and _experience.analytics.session.num found in the x2019_summit_platform_lab_2_midvalues dataset and apply LIMIT 10.
=> SELECT
endUserIds._experience.aaid.id,
_experience.analytics.session.num
FROM x2019_summit_platform_lab_2_midvalues_1
LIMIT 10;ERROR: ErrorCode: 08P01 sessionId: aa449e99-205e-4dc4-bef7-501722f33afe queryId: 0f699db7-3297-4bd2-ac7f-4e8922d5e819 Unknown error encountered. Reason: [No such struct field session in customDimensions, event1to100, environment; line 3 pos 2]
Did you receive this error? Reason: [No such struct field session in customDimensions, event1to100, environment; line 3 pos 58]
The error message means the Query Service could not find the field in the current dataset. The _experience.analytics.session field is not available in the midvalues dataset because it's only generated during the post processing stage of Adobe Analytics.
Pro Tip! The error message also contains the details for the fields that are available. This can be a useful reference when you aren't sure how to spell the field or if you aren't familiar with what the object contains.
The sessionization ADF is called SESS_TIMEOUT(<TIMESTAMP_COLUMN>, <NUMBER_OF_SECONDS>) and operates over a standard SQL window function.
A window function updates an aggregation and provides every row in your ordered subset or rows. The most basic aggregation function is SUM(). SUM() takes your rows and gives you one total. If you instead apply SUM() to a window, turning it into a window function, you receive a cumulative sum with each row.
The majority of the Spark SQL helpers are window functions that are updated with each row in your window, with the state of that row added.
Here's an example:
SELECT
endUserIds._experience.aaid.id,
timestamp,
SESS_TIMEOUT(ts, 60 * 30)
OVER (PARTITION BY endUserIds._experience.aaid.id
ORDER BY timestamp
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS sess
FROM experience_events
ORDER BY endUserIds._experience.mcid.id, timestamp ASC
Apply the SESS_TIMEOUT() to your query by replacing the _experience.analytics.session.num column reference.
=> SELECT
endUserIds._experience.aaid.id,
SESS_TIMEOUT(timestamp, 60 * 30)
OVER (PARTITION BY endUserIds._experience.aaid.id
ORDER BY timestamp
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS sess
FROM x2019_summit_platform_lab_2_midvalues_1
LIMIT 10;
id | sess
----------------------------------+-----------------
2DAFCA0D05032893-60001198A00703A4 | (0,1,true,1)
2DAFCA0D05032893-60001198A00703A4 | (6,1,false,2)
2DAFCA0D05032893-60001198A00703A4 | (6,1,false,3)
2DAFCA0D05032893-60001198A00703A4 | (155,1,false,4)
2DAFCA0D05032893-60001198A00703A4 | (5,1,false,5)
2DAFCA0D05032893-60001198A00703A4 | (2,1,false,6)
2DAFCA0D05032893-60001198A00703A4 | (3,1,false,7)
2DAFCA0D05032893-60001198A00703A4 | (5,1,false,8)
2DAFCA0D05032893-60001198A00703A4 | (7,1,false,9)
2DAFCA0D05032893-60001198A00703A4 | (4,1,false,10)
(10 rows)
The SESS_TIMEOUT() returns more than just a simple session number. Let's review it:
| Parameter | Description |
|---|---|
timestamp_diff |
Time in seconds between current record and last record |
num |
A unqiue session number, starting at 1, for the key defined in the PARTITION BY of the window function. |
is_new |
A boolean used to identify if a record is the first of a session |
| depth | Depth of the current record within the session |
Wrap your SELECT statement in another SELECT creating a subquery that uses the SESS_TIMEOUT() as a dataset preparation setp to create a new sess column. Keep the LIMIT defined in the top SELECT.
=> SELECT
*
FROM
(
SELECT
endUserIds._experience.aaid.id,
SESS_TIMEOUT(timestamp, 60 * 30)
OVER (PARTITION BY endUserIds._experience.aaid.id
ORDER BY timestamp
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS sess
FROM x2019_summit_platform_lab_2_midvalues_1
)
LIMIT 10;
id | sess
----------------------------------+-----------------
2DAFCA0D05032893-60001198A00703A4 | (0,1,true,1)
2DAFCA0D05032893-60001198A00703A4 | (6,1,false,2)
2DAFCA0D05032893-60001198A00703A4 | (6,1,false,3)
2DAFCA0D05032893-60001198A00703A4 | (155,1,false,4)
2DAFCA0D05032893-60001198A00703A4 | (5,1,false,5)
2DAFCA0D05032893-60001198A00703A4 | (2,1,false,6)
2DAFCA0D05032893-60001198A00703A4 | (3,1,false,7)
2DAFCA0D05032893-60001198A00703A4 | (5,1,false,8)
2DAFCA0D05032893-60001198A00703A4 | (7,1,false,9)
2DAFCA0D05032893-60001198A00703A4 | (4,1,false,10)
(10 rows)
Update your SELECT statement to COUNT the number of DISTINCT sessions per Analytics id. Use the columns from your subquery id and sess. And apply an descending ORDER BY on the count of sessions.
=> SELECT
id,
COUNT (DISTINCT id || sess.num) as Sessions
FROM
(
SELECT
endUserIds._experience.aaid.id,
SESS_TIMEOUT(timestamp, 60 * 30)
OVER (PARTITION BY endUserIds._experience.aaid.id
ORDER BY timestamp
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS sess
FROM x2019_summit_platform_lab_2_midvalues_1
)
GROUP BY id
ORDER BY Sessions DESC
LIMIT 10;
id | Sessions
----------------------------------+----------
F76936F2A1BB765-23003507DD57D25C | 32
1A852847F898863C-2230888AC08CC6CA | 29
2D12F90385030B1F-4000119540004E87 | 26
64449A583EFBBAC4-33B85A73A761912C | 19
743DDCAEEFAA626-1F1BF385BE8E56F0 | 19
2DB6583085037D0E-6000118980009348 | 9
262829FEE1877650-739AE7BB12BDF2CE | 9
2C41063E053168E9-4000012AC0023B0B | 9
2DBE2AAB0503181F-40001192600A3AAB | 8
491E8C757C07DD28-F4E287B4BC77B5F | 8
(10 rows)
Try a different a session timeout setting of 5 minutes rather than the examples 30 minutes. This might be something your mobile team would appreciate because the user experience is designed around quick engagements and workflows.
=> SELECT
id,
COUNT (DISTINCT id || sess.num) as Sessions
FROM
(
SELECT
endUserIds._experience.aaid.id,
SESS_TIMEOUT(timestamp, 60 * 5)
OVER (PARTITION BY endUserIds._experience.aaid.id
ORDER BY timestamp
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS sess
FROM x2019_summit_platform_lab_2_midvalues_1
)
GROUP BY id
ORDER BY Sessions DESC
LIMIT 10;
id | Sessions
----------------------------------+----------
2D12F90385030B1F-4000119540004E87 | 56
1A852847F898863C-2230888AC08CC6CA | 56
F76936F2A1BB765-23003507DD57D25C | 34
743DDCAEEFAA626-1F1BF385BE8E56F0 | 24
64449A583EFBBAC4-33B85A73A761912C | 23
69DB6DDA52734A24-36DD04D7ED2D9663 | 18
2DB6583085037D0E-6000118980009348 | 12
491E8C757C07DD28-F4E287B4BC77B5F | 12
2DBE2AAB0503181F-40001192600A3AAB | 11
2C41063E053168E9-4000012AC0023B0B | 11
(10 rows)
A command line interface to query data is exciting but it doesn't present well. In this lesson, we will guide you through a recommended workflow for how you can use Microsoft Power BI Desktop directly the Query Service to create visual reports for your stakeholders.
The complexity of your query will impact how long it takes for the Query Service to return results. And when querying directly from the command line or other solutions like Microsoft Power BI the Query Service is configured with a 5 minute timeout (600 seconds). And in certain cases these solutions will be configured with shorter timeouts. To run larger queries and front load the time it takes to return results we offer a feature to generate a dataset from the query results. This feature utilizes the standard SQL feature know as Create Table As Select (CTAS). It is available in the Platform UI from the Query List and also available to be run directly from the command line with PSQL.
Run the following SQL statements in the command line. be sure to put a comment inside of the SELECT statement with your station number so you can find your query later in the UI.
/* Daily_Trend */
SELECT
/* your station number */
date_format( from_utc_timestamp( timestamp , 'PST') , 'yyyy-MM-dd') AS Day,
CAST( COUNT (DISTINCT endUserIds._experience.aaid.id) AS STRING ) AS visitors,
CAST( COUNT (DISTINCT endUserIds._experience.aaid.id || _experience.analytics.session.num) AS STRING ) AS visits,
CAST( IFNULL( SUM( web.webPageDetails.pageviews.value ), 0 ) AS STRING ) AS pageViews,
CAST( IFNULL( SUM( commerce.purchases.value ), 0 ) AS STRING ) AS orders
FROM x2019_summit_platform_lab_2_postvalues_1
WHERE
( ( _ACP_YEAR = date_format( NOW() , 'yyyy') AND ( _ACP_MONTH = date_format( NOW() , 'MM') ) ) OR ( _ACP_YEAR = date_format( add_months( NOW(), -1 ) , 'yyyy') AND ( _ACP_MONTH = date_format( add_months( NOW(), -1 ) , 'MM') ) ) )
AND from_utc_timestamp( timestamp , 'PST') >= date_format( from_utc_timestamp( NOW() , 'PST') , 'yyyy-MM')
GROUP BY Day
ORDER BY Day ASC
LIMIT 31;/* Top_Pages */
SELECT
/* your station number */
web.webPageDetails.name AS PageName,
CAST( COUNT (DISTINCT endUserIds._experience.aaid.id) AS STRING ) AS visitors,
CAST( COUNT (DISTINCT endUserIds._experience.aaid.id || _experience.analytics.session.num) AS STRING ) AS visits,
CAST( IFNULL( SUM(web.webPageDetails.pageviews.value), 0 ) AS STRING ) AS pageViews
FROM x2019_summit_platform_lab_2_postvalues_1
WHERE
( ( _ACP_YEAR = date_format( NOW() , 'yyyy') AND ( _ACP_MONTH = date_format( NOW() , 'MM') ) ) OR ( _ACP_YEAR = date_format( add_months( NOW(), -1 ) , 'yyyy') AND ( _ACP_MONTH = date_format( add_months( NOW(), -1 ) , 'MM') ) ) )
AND from_utc_timestamp( timestamp , 'PST') >= date_format( from_utc_timestamp( NOW() , 'PST') , 'yyyy-MM')
GROUP BY PageName
ORDER BY IFNULL( SUM(web.webPageDetails.pageviews.value), 0 ) DESC
LIMIT 50;/* Month_Total */
SELECT
/* your station number */
date_format( from_utc_timestamp( timestamp , 'PST') , 'yyyy-MM') AS Month,
CAST( COUNT (DISTINCT endUserIds._experience.aaid.id) AS STRING ) AS visitors,
CAST( COUNT (DISTINCT endUserIds._experience.aaid.id || _experience.analytics.session.num) AS STRING ) AS visits,
CAST( IFNULL( SUM( web.webPageDetails.pageviews.value ), 0 ) AS STRING ) AS pageViews,
CAST( IFNULL( SUM( commerce.purchases.value ), 0 ) AS STRING ) AS orders
FROM x2019_summit_platform_lab_2_postvalues_1
WHERE
( ( _ACP_YEAR = date_format( NOW() , 'yyyy') AND ( _ACP_MONTH = date_format( NOW() , 'MM') ) ) OR ( _ACP_YEAR = date_format( add_months( NOW(), -1 ) , 'yyyy') AND ( _ACP_MONTH = date_format( add_months( NOW(), -1 ) , 'MM') ) ) )
AND from_utc_timestamp( timestamp , 'PST') >= date_format( from_utc_timestamp( NOW() , 'PST') , 'yyyy-MM')
GROUP BY Month
ORDER BY Month ASC
LIMIT 2;Navigate to the Platform UI - https://platform.adobe.com
Make sure you are viewing Queries
Search for your queries by putting your station number in the search field
Click on one of the three queries and then click on the "Output Dataset" link in the right.
Enter the appropriate name for your new table and replace the <uniqueidentifier> with your lab user number. Click Run Query. Repeat for the other two queries.
Daily_Trend_<uniqueidentifier>
Top_Pages_<uniqueidentifier>
Month_Total_<uniqueidentifier>

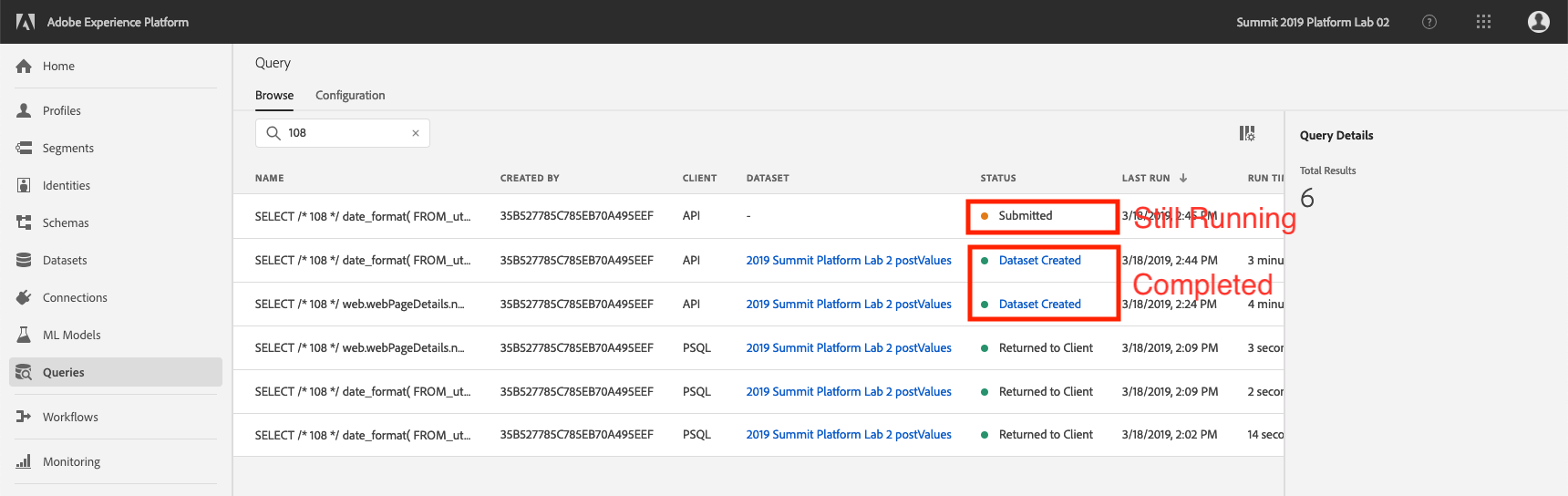
Observe the new queries that are created, and refresh the page to watch the status change. After they all show Dataset Created move on to the next exercise.
Launch Microsoft Power BI Desktop from the Start menu.
In the Start Page, select Get Data

In the Get Data dialog, find and select the PostgreSQL database connector and then click Connect.

Enter platformlab02.platform-query.adobe.io:80 for the Server and all for the Database. Then click OK.
IMPORTANT Be sure to include port ':80' at the end of the Server value because the Query Service does not currently use the default PostgreSQL port of 5432
In the next dialog populate the User name and Password with your Username (ending in @AdobeOrg) and Password found in the Configuration section of the Platform UI.
In the Navigator dialog, put your station number in the search field to locate your CTAS datasets and check the box next to each. Then click Load.
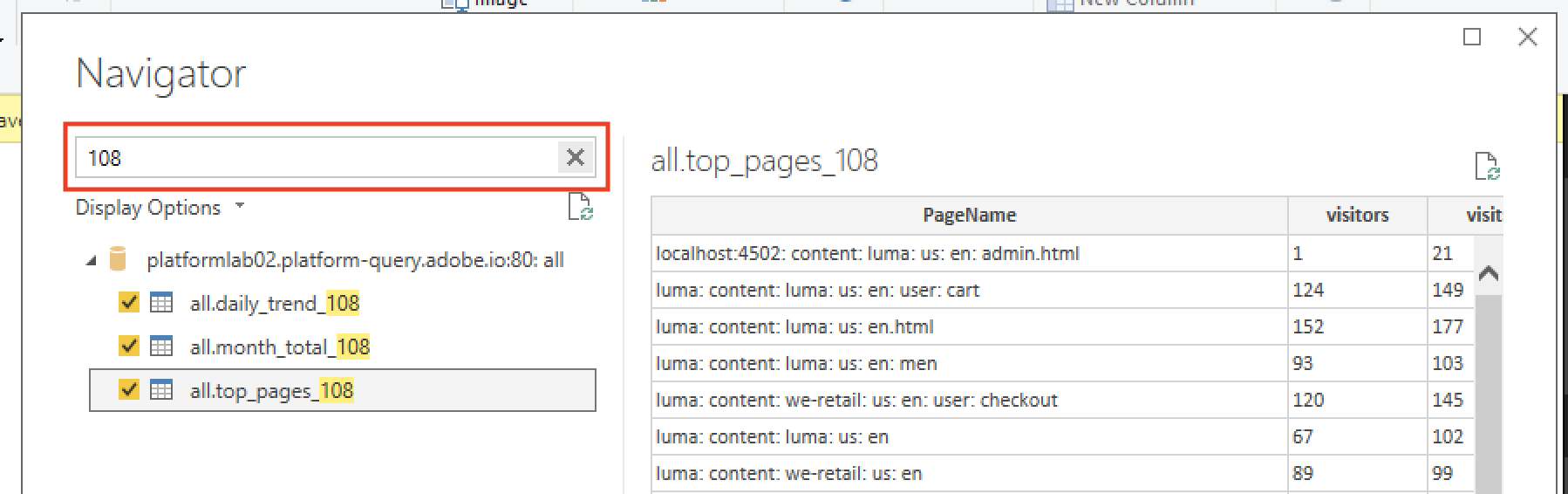
After the datasets are successfully loaded into Power BI you'll find them in the right column labeled FIELDS.

Over the next set of steps we perform data transformations in Power BI to prepare the data for visualization.
Hover over your Daily_Trend table, click the ellipsis to the right ... and select Edit query.

Click the header of the Day column to highlight it.
Navigate to the Transform tab and click the dropdown item Data Type: Text to expand it. Then select Date.

The value will change from YYYY-MM-DD to M/D/YYYY
For each remaining column, select it and then set the Data Type to Whole Number.
visitors, visits, pageViews, orders
Pro Tip! You can select multiple columns by holding down the
SHIFTkey while clicking and then apply the Data Type change to the selected group.
Repeat steps 3 and 4 to the appropriate columns in your Top_Pages and Month_Total table.
Navigate to the Home tab and click Close & Apply.
Now Power BI will recognize those columns as Dates and Whole Numbers when we create our visualizations. Let's start building our report.
Expand the Daily_Trend dataset by click on the dataset name.
Check the Day and visitors fields.
See how the visualization appear in the canvas to the left. Since Power BI knows the field formats it's auto-selected a visualization but it also defaulted to grouping our date by Year. Let's update that and have it reflect the day.
Under the column Visualizations next to the Fields column find the Axis section. Click the arrow next to the top-level Day and select Day from the context menu.

Keep the current visualization highlighted in the canvas. Check the boxes next to the remaining traffic metrics; visits and pageViews.
Deselect the visualization in the cavans by clicking aware in the empty canvas area. Then check the boxes for Day and orders.
Apply the same changes from step 3. Under the column Visualizations next to the Fields column find the Axis section. Click the arrow next to the top-level Day and select Day from the context menu.
Deselect the current visualization. Expand your Top_Pages dataset and check all the fields.
Power BI automatically used the Table visualization for this data. Resize the visualizations as needed.
Deselect the visualization and walk through these steps for each of the metrics in the Month_Total dataset.
orders, visitors, visits, pageViews
Visualizations column, find and select the Card visualization type.
You can find out more about visualizations in Power BI Desktop in the following tutorial:
Introduction to visuals in Power BI: https://docs.microsoft.com/en-us/power-bi/guided-learning/visualizations?tutorial-step=1
Optional
Now that you have got the basics of Query Service down, and you have built a dashboard in Power BI, we will try a few more advanced use cases if there is time. Query Service has the ability to perform JOINs using mappings available in Adobe Experience Platform Identity Service and then generate new, multi-channel reporting datasets. There are also additional Adobe-Defined Functions which can be used as shortcuts for common tasks. You will have the chance to try out these features now.
Let's start with a simple query over our Analytics postvalues dataset x2019_summit_platform_lab_2_postvalues_1 to find the totals for visitors, visits and page views. And then we can JOIN it with a couple other datasets to break it down by our customer's loyalty levels.
Write a query to count the visitors, visits, and page views using the following fields endUserIds._experience.mcid.id, _experience.analytics.session.num, and web.webPageDetails.pageViews.value from the dataset x2019_summit_platform_lab_2_postvalues_1.
SELECT
COUNT(DISTINCT endUserIds._experience.mcid.id) AS visitors,
COUNT(DISTINCT endUserIds._experience.mcid.id || _experience.analytics.session.num) AS visits,
COUNT(web.webPageDetails.pageViews.value) AS pageViews
FROM x2019_summit_platform_lab_2_postvalues_1
LIMIT 10;visitors | visits | pageViews
---------+--------+-----------
394 | 1062 | 10414
(1 row)
The customer loyatly information is loaded in a separate dataset called clone_old_luma_loyalty_system. Write a query to return 10 sample records for the _customer.default.loyalty.level and identities fields from the clone_old_luma_loyalty_system dataset.
level | identities
---------+-----------------------------------------------------------
PLATINUM | (NULL,mja@adobetest.com,NULL,true,"(email)")
PLATINUM | (NULL,test023@adobetest.com,NULL,true,"(email)")
GOLD | (NULL,test020@adobetest.com,NULL,true,"(email)")
PLATINUM | (NULL,prewwsc1@adobetest.com,NULL,true,"(email)")
PLATINUM | (NULL,test026@adobetest.com,NULL,true,"(email)")
GOLD | (NULL,test003@adobetest.com,NULL,true,"(email)")
GOLD | (NULL,test001@adobetest.com,NULL,true,"(email)")
GOLD | (NULL,test004@adobetest.com,NULL,true,"(email)")
GOLD | (NULL,test007@adobetest.com,NULL,true,"(email)")
GOLD | (NULL,test019@adobetest.com,NULL,true,"(email)")
(10 rows)
To JOIN the loyalty data with the Analytics data we need find a common identity field but because we don't collect the email in our Analytics datasets we won't be able to JOIN directly to the Loyalty dataset. Fortunately, we have another dataset loaded called clone_old_luma_web_mobile_account_1 that has two columns we can use to establish a link between the email and Experience Cloud ID
Write a query to return 10 sample records for the personalEmail.address and identities[0] fields from the clone_old_luma_web_mobile_account_1 dataset. The first item of identities is the Experience Cloud ID we will be able to JOIN with the Analytics dataset.
address | identities[0]
----------------------------------+------------------------------------------------------------------
hannouz+test023@adobetest.com | (NULL,66203667725822667647064118414878968875,NULL,NULL,"(ecid)")
hannouz+30@adobetest.com | (NULL,12054111184877472147210798365179230744,NULL,NULL,"(ecid)")
hannouz+30@adobetest.com | (NULL,31843238794710706547517049979667115527,NULL,NULL,"(ecid)")
ktukker+j@adobetest.com | (NULL,27806757926713727803198527942110554008,NULL,NULL,"(ecid)")
hannouz+2@adobetest.com | (NULL,34790985982934030960879673708557574920,NULL,NULL,"(ecid)")
hannouz+35@adobetest.com | (NULL,05906194997424882204174301767635315231,NULL,NULL,"(ecid)")
hannouz+test022@adobetest.com | (NULL,07949069291302237306224536734173698771,NULL,NULL,"(ecid)")
ktukker+20181119-01@adobetest.com | (NULL,20692311702755272796284690410371762188,NULL,NULL,"(ecid)")
hannouz+parse3@adobetest.com | (NULL,15796274745303166386328876801649284028,NULL,NULL,"(ecid)")
ktukker+mjackson@adobetest.com | (NULL,05941668419219809148698457778349146371,NULL,NULL,"(ecid)")
(10 rows)
Now let's use what we know to write an INNER JOIN on the clone_old_luma_web_mobile_account_1 and clone_old_luma_loyalty_system datasets to return an Experience Cloud ID with the customers loyalty level. Use the fields identities[0].id and personalEmail.address from the clone_old_luma_web_mobile_account_1 dataset. Use the fields _customer.default.loyalty.level and identities[0].id from the clone_old_luma_loyalty_system dataset.
An INNER JOIN selects all rows from both datasets as long as there is a match between the columns.
SELECT
DISTINCT bar.identities[0].id AS ecid,
foo._customer.default.loyalty.level AS loyaltyLevel
FROM clone_old_luma_web_mobile_account_1 AS bar
INNER JOIN clone_old_luma_loyalty_system AS foo
ON (bar.personalEmail.address = foo.identities[0].id)
WHERE bar.personalEmail.address IS NOT NULL LIMIT 10; ecid | loyaltyLevel
----------------------------------------+--------------
18188458278739463648210329911351443173 | PLATINUM
86423653257538625495284038844636972284 | GOLD
69758288672830733567012497741392897355 | GOLD
04545314134737877022174609346799535661 | GOLD
34203421735685126396224440169659836088 | PLATINUM
80947343348075908365611877850341816093 | PLATINUM
44453189842500155188631579128204774448 | PLATINUM
41862970467520163289215260025592858531 | PLATINUM
57258050937438402865372747001254912427 | PLATINUM
49701614298328770186345737332633601240 | PLATINUM
(10 rows)
Now JOIN the query from the last step and the first step of this exercise to produce a result that groups the visitors, visits, and page views by the customer loyalty levels.
Use an INNER JOIN on the x2019_summit_platform_lab_2_postvalues_1 dataset and subquery from the JOIN of the clone_old_luma_web_mobile_account_1 and clone_old_luma_loyalty_system datasets, in the last step. You will use the endUserIds._experience.mcid.id field from the x2019_summit_platform_lab_2_postvalues_1 and the resulting id (or ecid, if AS ecid was declared) from the subquery to qualify the INNER JOIN.
SELECT
b.loyaltyLevel AS LoyaltyLevel,
COUNT(DISTINCT endUserIds._experience.mcid.id) AS visitors,
COUNT(DISTINCT endUserIds._experience.mcid.id || _experience.analytics.session.num) AS visits,
COUNT(web.webPageDetails.pageViews.value) as pageViews
FROM x2019_summit_platform_lab_2_postvalues_1 AS a
INNER JOIN
(
SELECT DISTINCT bar.identities[0].id AS ecid,
foo._customer.default.loyalty.level AS loyaltyLevel
FROM clone_old_luma_web_mobile_account_1 AS bar
INNER JOIN clone_old_luma_loyalty_system AS foo
ON (bar.personalEmail.address = foo.identities[0].id)
WHERE bar.personalEmail.address IS NOT NULL
) AS b
ON (a.endUserIds._experience.mcid.id = b.ecid)
GROUP BY b.loyaltyLevel
LIMIT 10;LoyaltyLevel | visitors | visits | pageViews
-------------+----------+--------+-----------
GOLD | 1 | 10 | 34
PLATINUM | 4 | 20 | 69
(2 rows)
Some analysis use cases require you to identify the time between each event and some base event that happened in the past. There are also use cases where you want to take a series of events and measure the time between them and another base event that happened later. The Time Between Adobe-Defined Function provides the ability to measure both. Let's start with measuring the time after a particular event.
Here's the syntax for the function when looking forward:
TIME_BETWEEN_PREVIOUS_MATCH(time, eventDefintion, [timeUnit]) OVER ([partition] [order] [frame])
Write a query that uses the TIME_BETWEEN_PREVIOUS_MATCH function. It will include parameters for time (timestamp), the definition of the event (in this case we are looking for the first page - _experience.analytics.session.depth='1.0'), and how granular we want the time unit to be (seconds). We then define partitioning and ordering for the select
SELECT endUserIds._experience.mcid.id, _experience.analytics.session.num, _experience.analytics.session.depth, timestamp, web.webPageDetails.name,
TIME_BETWEEN_PREVIOUS_MATCH (timestamp, _experience.analytics.session.depth='1.0', 'seconds')
OVER (PARTITION BY endUserIds._experience.mcid.id, _experience.analytics.session.num
ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS seconds_since_first_page
FROM x2019_summit_platform_lab_2_postvalues_1
ORDER BY endUserIds._experience.mcid.id, _experience.analytics.session.num, timestamp ASC
LIMIT 10; id | num | depth | timestamp | name | seconds_since_first_page
---------------------------------------+-----+-------+-----------------------+------------------------------------------------------------------------------------------------------+--------------------------
00118886674762620790046721575618274510 | 1 | 1 | 2019-03-18 21:05:51.0 | luma: content: luma: us: en | 0
00118886674762620790046721575618274510 | 1 | 2 | 2019-03-18 21:06:00.0 | luma: content: luma: us: en: community: signin | 9
00118886674762620790046721575618274510 | 1 | 3 | 2019-03-18 21:06:03.0 | luma: content: luma: us: en: community: signup | 12
00118886674762620790046721575618274510 | 1 | 4 | 2019-03-18 21:06:45.0 | luma: content: luma: us: en: community: signin | 54
00118886674762620790046721575618274510 | 1 | 5 | 2019-03-18 21:07:25.0 | luma: content: luma: us: en | 94
00118886674762620790046721575618274510 | 1 | 6 | 2019-03-18 21:07:27.0 | luma: content: luma: us: en: community: signin | 96
00118886674762620790046721575618274510 | 1 | 7 | 2019-03-18 21:08:00.0 | luma: content: luma: us: en | 129
00118886674762620790046721575618274510 | 1 | 8 | 2019-03-18 21:08:14.0 | luma: content: luma: us: en: user: account | 143
00118886674762620790046721575618274510 | 1 | 9 | 2019-03-18 21:08:18.0 | luma: content: luma: us: en: community: profile.html: home: users: community: s: 45bcbnvbj3dpwayz98x | 147
00118886674762620790046721575618274510 | 1 | 10 | 2019-03-18 21:11:29.0 | luma: content: luma: us: en: user: account | 338
(10 rows)
Now let's look at a different event. We'll look for values in _experience.analytics.event1to100.event2, which is an Analytics event, then we will look forward to measure the time between the current hit and the event we are looking for. Here's the query:
SELECT endUserIds._experience.mcid.id, _experience.analytics.session.num, timestamp, web.webPageDetails.name,
TIME_BETWEEN_PREVIOUS_MATCH (timestamp, _experience.analytics.event1to100.event2.value IS NOT NULL, 'seconds')
OVER (PARTITION BY endUserIds._experience.mcid.id, _experience.analytics.session.num
ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS seconds_since_event2
FROM x2019_summit_platform_lab_2_postvalues_1
ORDER BY endUserIds._experience.mcid.id, _experience.analytics.session.num, timestamp ASC
LIMIT 100; id | num | timestamp | name | seconds_since_event2
----------------------------------------+-----+-----------------------+------------------------------------------------------------------------------------------------------+----------------------
01181109909502831418920943169980309961 | 1 | 2019-03-18 15:15:07.0 | luma: content: luma: us: en: products: men: bottoms: shorts: orestes-fitness-short | 0
01181109909502831418920943169980309961 | 1 | 2019-03-18 15:15:12.0 | luma: content: luma: us: en: products: men: bottoms: shorts: arcadio-gym-short.html: llmsh11 | 0
01181109909502831418920943169980309961 | 1 | 2019-03-18 15:15:16.0 | luma: content: luma: us: en: community: signin | 4
01181109909502831418920943169980309961 | 1 | 2019-03-18 15:15:21.0 | luma: content: luma: us: en: community: signup | 9
01181109909502831418920943169980309961 | 2 | 2019-03-18 16:55:38.0 | luma: content: luma: us: en: community: signin |
01181109909502831418920943169980309961 | 2 | 2019-03-18 16:56:04.0 | luma: content: luma: us: en: community: profile.html: home: users: community: o: py9a4xjzjnj91q0xvh7 |
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:05:20.0 | luma: content: luma: us: en: products: gear: bags: fusion-backpack | 0
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:05:29.0 | luma: content: luma: us: en: products: gear: bags | 9
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:05:33.0 | luma: content: luma: us: en: men | 13
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:05:35.0 | luma: content: luma: us: en: products: men | 15
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:05:37.0 | luma: content: luma: us: en: products: men: bottoms | 17
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:05:41.0 | luma: content: luma: us: en: products: men: bottoms: shorts: orestes-fitness-short | 0
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:05:44.0 | | 3
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:05:54.0 | luma: content: luma: us: en: user: cart | 13
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:05:58.0 | luma: content: we-retail: us: en: user: checkout | 17
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:07:08.0 | luma: content: we-retail: us: en: user: checkout: order | 87
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:07:13.0 | luma: content: we-retail: us: en: user: checkout: order: thank-you.html | 92
01496391228848527781511949642232697538 | 1 | 2019-03-04 16:07:17.0 | luma: content: we-retail: us: en | 96
You will note that some events do not have a time listed in the results because those sessions don't have the event we are looking for.
🏆 Congratulations - You made it!
We would really appreciate your feedback at the survey link below. Survey respondents will be entered into a drawing for a $50 Amazon gift card. The survey will remain active until Monday, April 1, 2019: https://bit.ly/2Oif62C
Query Service is moving out of Alpha and into a Proof of Concept phase in the Summer. If you are interested in learning more about this functionality, please let your Adobe Account Executive or sales person know.
Adobe Analytics field mapping to ExperienceEvent XDM: https://www.adobe.io/apis/experienceplatform/home/services/query-service/query-service.html#!acpdr/end-user/markdown/query-service/solutionref/analytics-field-map.md
Adobe Experience Platform Query Service documentation: https://www.adobe.io/apis/experienceplatform/home/services/query-service/query-service.html